我和MindOS在RAG上的探索
- 9 minsRAG现在已经是一个大模型相关应用领域不可能避免的话题或者技术。Mindverse算是工业界里接触这个事儿相对比较早的,以及年关将至,想写些总结文档,但启动的时候第一个想法是不想把总结文档写的很虚很大(先讲生态,再讲大局,吹些认知,也许有些ptsd),所以不如把自己的探索经历朴实的分享一下。
首先声明下,本文中或者是我们主要探索的RAG的方向是真正的RAG领域的一部分,并不涉及对于语言模型的参数调整,也是我们认为最最适合当前大模型应用生态的方案。
并且我还有一个想法,随着模型能力的提升,RAG的重要性也会越来越多,会形成企业数据(多模态)搜索引擎和个人数据(多模态)搜索引擎。
对于个人数据而言,RAG将不再完全侧重于知识类的召回,还会存在很多用户个人习惯,历史对话记录等相关的召回。
RAG的优化阶段
基础的文档的召回
- parsing
- txt(无需解析)
- PDF:
- 开源工具(质量比较低)
- Adobe官方解析API(质量高,结构会有不一致)
- Markdown(无需额外解析)
- Html
- chunking
- 标题
- summary
- 内容分段落
- Markdown可以根据一些特殊标识符 + 分段
- 超参:
- chunk size(也有很多的约束的,除了embedding 模型接受的序列长度之外,还有后续链路的需求。后面会提到)
- overlapping的size
- indexing
- 调用ada embedding得到
- 存到es或者一些常见的向量数据库中
- recalling
- 首先对用户输入的语言进行同样的embedding提取,然后通过业内比较通用的方法BM25 + Embedding ensemble的方案来进行最相关的chunk的召回。(说的高端一点就是sparse embedding和dense embedding)
- generating
- 将返回的chunk组装成合适的prompt输入给大模型进行生成。
💡 方案总结
第一阶段是一个快速通链路,也是一些非专注于RAG的开源项目使用的比较标准的方案。他的主要优点就是打通整个链路特别快,没有什么复杂逻辑,并且能在知识量不大,混淆度一般的情况handle更多情况,充分适配了LLM本身,连特性上也是——做60分很容易,做80分就需要系统化的思考。
它的缺点就是:
- 建索引的时候还是比较粗暴的,对于量大,有混淆性的文本一般挺难区分出来的。
- 查询的时候,因为是在对话中的查询,直接拿当前轮的对话很容易缺少信息。如果拿多轮上下文直接进行查询,需要单独训练模型,因为这是一种特殊的查询模式。
基于多文档与对话流的深度优化
MindOS在很早的时候上线了相关的功能(具体时间忘了,但是我记得那时候llama index这个开源项目还是它原来的名字gpt index)
结合用户的反馈,以及初期我们面向的企业级用户的需求,我们进行了深度的分析和探索。对于搜索相关的命题,都有一个重要的基础逻辑,即离线的indexing环节可以做重,因为成本是一次性的。但在线的检索环节不能因为离线的indexing环节也变重。
基于从离线到在线使用的每一个阶段的拆解,进一步对效果进行了提升:
- parsing
- 暂无特殊的优化
- chunking
- 大小chunk逻辑:观察真实的文档使用,我们发现由于特定格式 + token数量的共存逻辑切分,会导致知识点不全的情况,在线的二次补全又比较浪费时间。所以我们做了分级的chunking,小chunk用来做召回,大chunk是真正返回给大模型进行生成的。
- 定制优化:额外的,因为真实情况下,文档中会有很多种格式,而初期我们的重点没有放在多模态上,所以主要针对的是一些表格类数据chunking的完整性额外优化。
- Indexing 在indexing环节,我们进行了很多尝试。
- chunk层面:我们针对每个参与召回的chunk,都进行了知识点提取,再将知识点作为chunk的对外勾子,给实时的检索做更多的信息参考。
- 文档层面:我们进行了聚类,以便做一些分级的查询,避免过度召回导致precision低,对大模型造成了干扰和困惑。
不过后来因为成本问题以及转向了c端的用户,文档没有那么多的原因,都将这些优化进行了回滚。
- recalling 这个部分是在这个阶段带来最大改动收获的。
- 上下文召回意图生成 上面说到因为联想需求(检索需求)往往都是在对话流中产生的,所以必须结合上下文才能得到充分理解用户意图的query。在这里,我们增加了一个query rewrite环节(会在一定程度上增加用户的等待时间),即用大模型去理解上下文,去识别:
- 用户是否需要查询知识库
- 应该查询哪些文档【踩坑预警,最开始的目的是为了缓解相似知识过度召回的现象,虽然起了一定的作用,但也因为只使用标题和summary等meta info判断,导致了面向细节知识查询时,大模型判断失败】
- 用户的真实查询语句应该是怎么样的(甚至可以是多条的,比如对比a和b两种商品,应该把两者信息都拿到)
实际上这样做又增加了一个额外的好处,就是可以调整让大模型生成一个和做indexing时候更加接近的查询格式。进一步提高了召回和准确率。
- rank模块的加入 最开始我们回避了rank模块。主要有两个原因:
- 在认知范围内不存在一个通用语义上的rank模块
- 通过有限的数据训练一个rank模块在真实的业务使用上,很容易遇到与训练数据分布不一致的情况,反而引入错误。
- 公司的重点资源不会投入到训练一个通用的ranking模块
- 我们认为大模型的生成环节本身就是一个rank模块
但是现状是:
- 我们面对的场景不只是一个知识问答场景,mindos作为一个通用平台,需要处理各种任务。所以大模型在生成环节能给的上下文窗口是有限的,且因为功能复杂,需要进一步给大模型肩负。
- 在经过一系列调研之后,我们发现了cohere提供了通用rank的api,并且效果还不错。成本和调用的时间也比较可控。
所以最后我们在生成之前还增加了一个ranking的模块。
- 上下文召回意图生成 上面说到因为联想需求(检索需求)往往都是在对话流中产生的,所以必须结合上下文才能得到充分理解用户意图的query。在这里,我们增加了一个query rewrite环节(会在一定程度上增加用户的等待时间),即用大模型去理解上下文,去识别:
- generating 这部分主要也是精细化调整。主要是针对我们的场景:
- 联想的知识更多的是参考而不是说必须表达。
- 部分论文也写到,对于大模型使用知识的效果,有两头好,中间轻的情况。对位置也进行了调整。
💡 方案总结
在经过上述的调整优化后,我们形成了如下的大致流程:
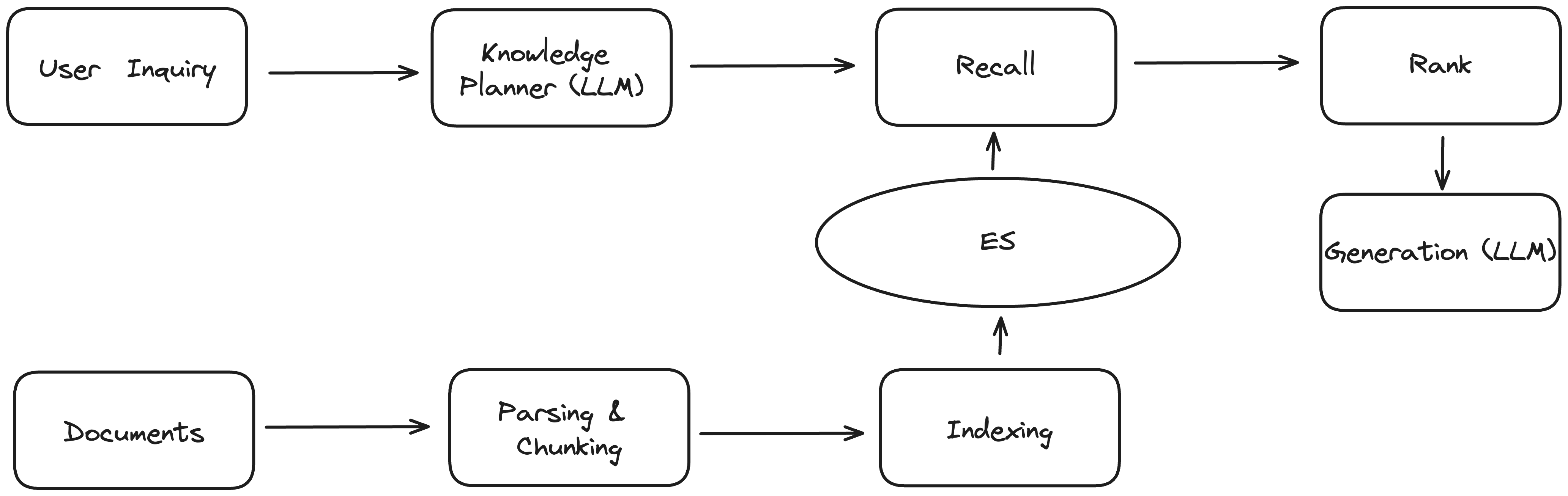
这个版本算是一个比较完整的,而且可用度比较高的一个版本了,能够满足大多数的用户需求。但是也存在了很多的缺陷:
- 对于推理型任务并不能很好的handle(实际上我们把这个任务卸载到了Agent整体的思维链路组织上)
- 对于多模态的文档,并不能做很好的理解。
我们也参考了llama index的项目中的一些用法,但是发现在面向C端用户时,一些非常复杂的用法并不符合用户的使用预期和标准。
额外的,我们的RAG系统,还会面对其他的考验:
- 平台功能复杂,有加重注意力的知识召回模式(我和Agent一起看文档),这个时候,主要的注意力应该放在所看的文档上,但是又不能忽视Agent本身的背景知识。
- 平台是个出海产品,对于多语言的情况,需要进行适配,否则如果改写只重视中英文的话,会影响召回的结果。
多模态的RAG
多模态的RAG我认为是当前阶段的重中之重。也是我带领MindOS技术团队正在推进的事情,这里由于还没有踩够足够的坑,所以只说大的逻辑:
- 不同类型的多模态文件,索引方式有所差别,但所有的meta info都应该包含一定的内容,否则会有检索困难。但是由于全量解析是需要消耗大量计算的,所以这里面需要做一些权衡和设计。
- 原本的RAG更加符合的是,多模态本身是想引入用户协同创作,在用户协同创作后,召回(搜索)方式应该更加多样。比如”我上个月去听的那场报告里的ppt”。涉及到了时间和事件作为检索条件。在这种情况下,不管是被动模式(联想),还是主动模式(搜索问答)都会升级到下一个模式。
其他
开源项目
Langchain(一个通用库,初学者尝鲜可用,广度很好)
LlamaIndex(我认知范围内最完整的RAG开源工具库,从基础到复杂,可以满足各种诉求)
推荐的其他应用
openai’s assistant api