LLM & Agent的持续挑战
- 10 mins距离Chatgpt正式发布不足一年,整个业界已经是有了天翻地覆的变化。
首先是各路大模型出世,从闭源的Claude,到开源的Llama,中国国内的文心一言、百川模型等。
然后是各种号称AI Native的平台和应用(如MindOS,Fiexi.ai,NexusGPT等等),开源项目如AutoGPT, MetaGPT,在中国人民大学团队的这篇paper里对这个方向的相关研究和开源工作做了比较详细的阐述。
到了今天,竞争已经十分白热化,据我了解,业内应该基本有这样的共识:
- 在应用层:AI + 比AI Native的应用,在这个早期阶段更加有落地价值,市面上并没有一个真正AI Native的生产力释放工具,或者说除了ChatGPT之外,没有一个Killer APP 产生。
- 随着开源生态的发展,包括预训练模型和训练工具的生态繁荣,没有本身业务的做中等规模(指10B左右规模的模型)的公司将毫无价值。
- 最高level的大模型,目前而言是工程研究领域的一大明珠,真正实现AGI的目前最可靠的路径。但是还有至少几年的路要走,包含多模态,大模型幻觉的降低等等。
因为我自己也身在这个局中,又恰好整个资本市场不是很景气,所以就凑一些空闲的时间,盘点一下自己对大模型 & Autonomous Agent生态未来方向的思考。
从底层大模型能力而言:
- 幻觉的降低。目前在大模型落地场景使用上,对于创意激发层面是做的相当不错的。然而在信息的“可靠性”上,因为生成模型本身的技术原因,会存在一定的hallucination。具体的表现就像杨笠(来自中国的一位脱口秀演员)“男人”,那么普通却又那么自信,对自己不确定的事情言之凿凿。而对于大部分商业/工业行为来说,说出的话就代表了公司/个人的态度,所以需要基本完全避免对应的情况。为了解决hallucination的问题,有两个方向的解决方法:
- Beyond LLM:这一类主要是在LLM之外,通过一些信息源或者更加复杂的机制来保证,本身不改变大模型的概率输出。
- 在LLM之外,增加可靠信息源(比如检索信息源),更进一步的,部分产品为了进一步提升grounding的能力,会指示大模型输出的时候增加引用,来更好的帮助使用者区分有据可依的部分和大模型凭空生成的部分。
- 利用更加复杂的思考模式,来进行更加可靠的推理:从COT到Self-Consistency,Tree-of-Thought,Self Reflection等。思考方式的示意图如下,图片来自论文:
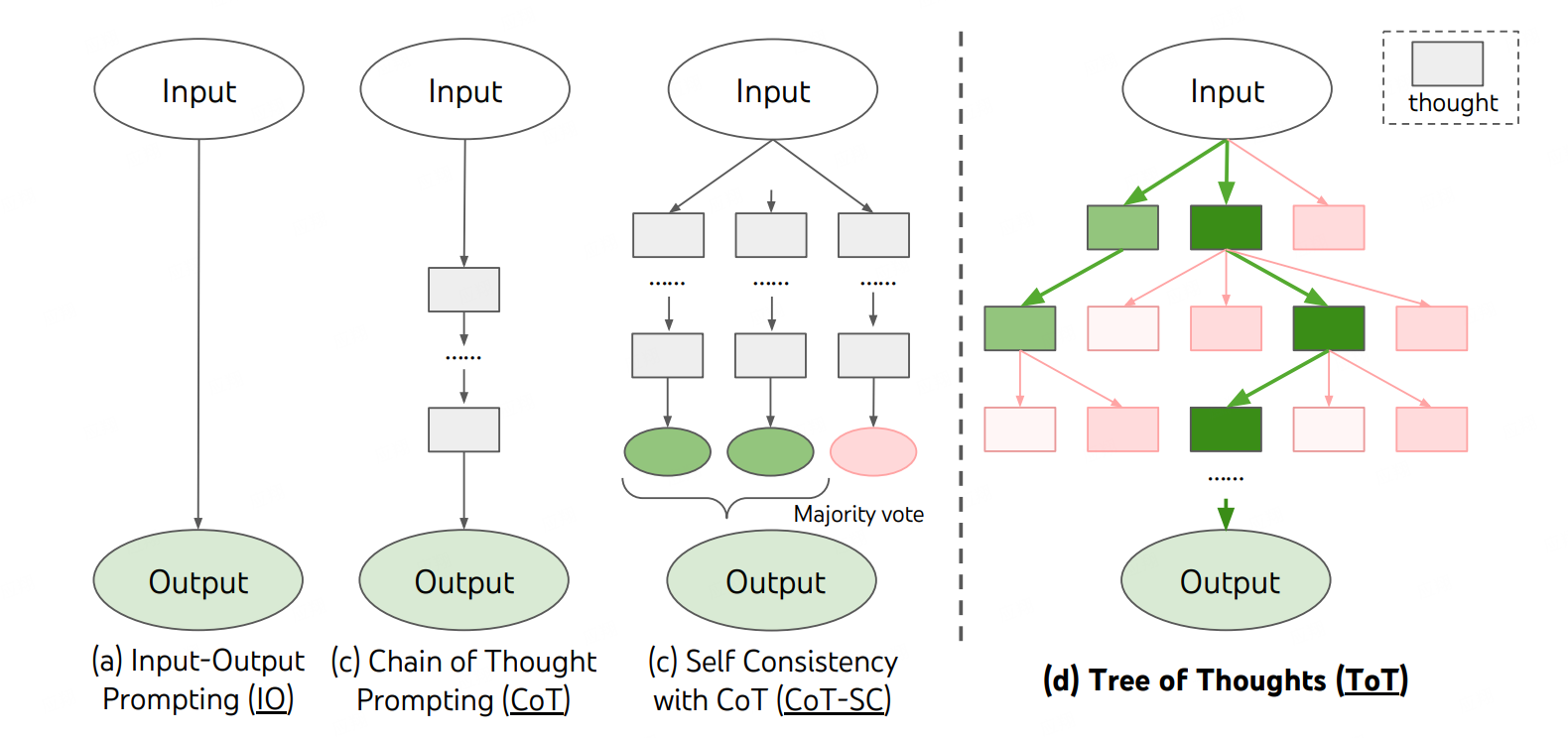
- LLM本身:如果在supervised training的环节里,模型能够看到所有的用户可能产生的问题,并且有ground truth(或者明确表示不知道)进行train,实际上也能降低幻觉。另外一个渠道是在RL的时候,通过rank model进行指导,对LLM align的目标进行调整。
- Beyond LLM:这一类主要是在LLM之外,通过一些信息源或者更加复杂的机制来保证,本身不改变大模型的概率输出。
- 多模态大模型的构建。如果想通过大模型的方式实现AGI,那么一定需要有多模态的输入输出能力。因为文本的训练给予模型的是认知能力、知识能力,但是对现实世界的理解和交互是需要多模态大模型的,文本在某些方面是对图像信息的有损压缩。目前也有很多公司和机构已经开始了这个方向的工作:
- Openai 的 GPT-4在最开始发布演示的时候就已经展示了多模态的理解能力,不过目前还没有正式对公众开放这一能力。
- Deepmind 的Flamingo,和智源的EMU。这两个模型的模型结构和训练方案基本是公开的。能够应对第一阶段的一些图文混合的需求。

- 特斯拉的视觉大模型,严格意义上来说,不太属于多模态的大模型,更像是人对于视觉输入转换成动作的直觉映射。但是由于个人感觉这个模型的输入输出转化,是未来AGI的一个重要组成部分,所以暂时也放进来。
总体来说,多模态大模型相比更加成熟的LLM,还处于更加早期的阶段,整体bar的上限也更高,大家一起拭目以待吧。
从底层大模型的产品化/工业化应用上:
- 推理效率的提升:大模型令人诟病的一点是不够亲民。在业务使用时,单次inference需要消耗的资源比较多,生成每一个token的时间也比较长。为了做到AI大模型普惠,很有必要让推理的效率进一步提升,资源进一步降低。目前主要相关的工作有:
- 推理速度:
- 算法上:最近比较流行的有speculative decoding,这个方法是通过小模型去生成,大模型验证和修复的过程来提速。
- 训练推理框架上:Deepspeed,Colossal AI,fastertransformer,fastchat等等这些都能在inference的时候提供一定的加速作用,当然需要注意的是,根据我踩的坑,fastertransformer会带来精度的下降虽然提速很明显,Deepspeed则不支持多卡的batch 推理,因为部分缓存会打乱。
- 推理资源:
- 量化是一个常规且重要的手段,既有助于推理速度的提升,也有助于消耗资源的减少。如现在的chatglm和llama,部分模型都能被用在个人主机上进行使用。
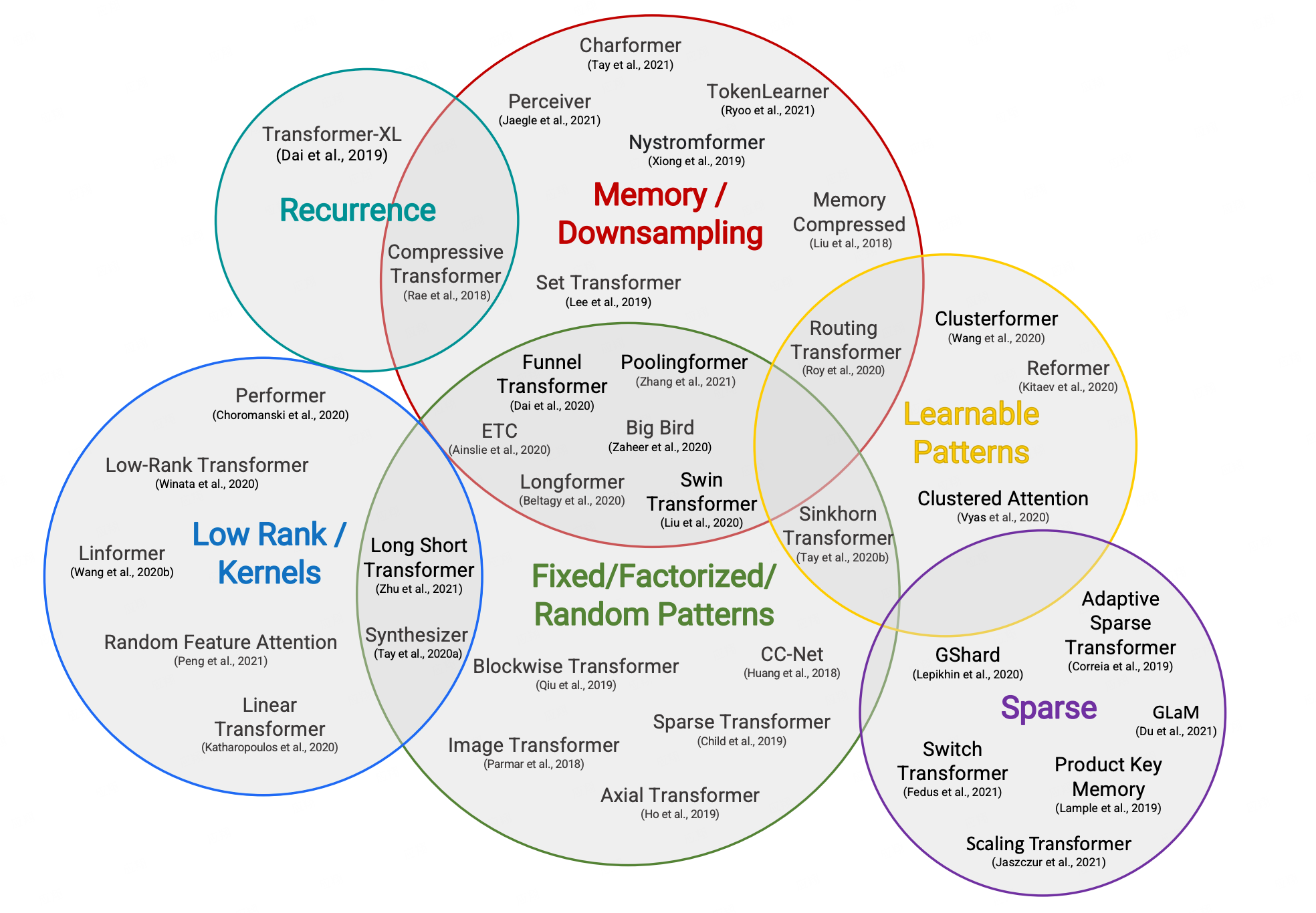
- 目前也有相当一部分算法研究工作,比如让Transformer更加的稀疏,或者说压缩Memory的使用。下图中的修改版transformer结构,在一定程度上都进行了计算和内存效率的提升。
- 推理速度:
- 训练效率和稳定性的提升:
- 因为没有具体针对大模型做过底层的pre training,并且这部分基本可以视为头部公司的机密,所以在实操上不是很清楚,但是根据业界的反馈来说超大规模(上千亿)模型训练的过程十分容易中断。提高稳定性对于。另外一个方向是通过分布式训练框架的生你家,最后一个就是等待Nvidia新的硬件。
- Context Window的加长
- 在具体的使用过程中,由于外部知识等的加入,以及上下文的加长,大模型prompt的长度限制带来的问题越来越明显。然而在pre train的过程中,如果拼命把context window拉长,那么训练成本将大大提高(平方),所以一个相对更好的方式是后置处理。目前看到相关的方法有基于Neural Tangent Kernel 的方法和 Position Interpolation两种。PI这种方法适用于使用了RoPE的模型结构,经过一定的tune之后,对效果也能有一个比较好的保持。
从Agent的上层使用来说:
目前Agent被认为是大模型的上层扩展,是大模型真正服务于场景的形态。为了真正能让Agent更好的服务用户,目前看下来有以下几个重要的发展方向是可以发力的(作为大家都深刻认识到的方向,planning等的能力这里暂时不提,它跟CoT, ToT等也是密切相关,之后细节讲agent的时候进行详细阐述):sd
- 上下文管理:上下文管理是Agent框架的重中之重,这里包含了上下文的记录、有效上下文的提取、适应于底层大模型的Prompt结构(第三点不赘述)。
- 上下文需要多元记录:对话上下文(当前session和历史对话)、技能执行上下文、知识上下文、用户Profile的上下文、Task执行上下文。并且上下文也包含了尺度,当Agent聚焦于局部任务时,最好的情况是注意力专注在局部上下文中。
- 为了解决有效上下文的提取,需要一个LLM时代的检索系统:最最本质的问题有两个 1)大模型的上下文窗口一定是有限的,而包括有价值的无价值的可用的信息是无限的;2)当上下文过多时,很容易造成注意力的紊乱,导致最后的推理效果不佳。为此,我们需要一个中间层来从大量驳杂的信息中提取出有效信息传递给底层大模型。
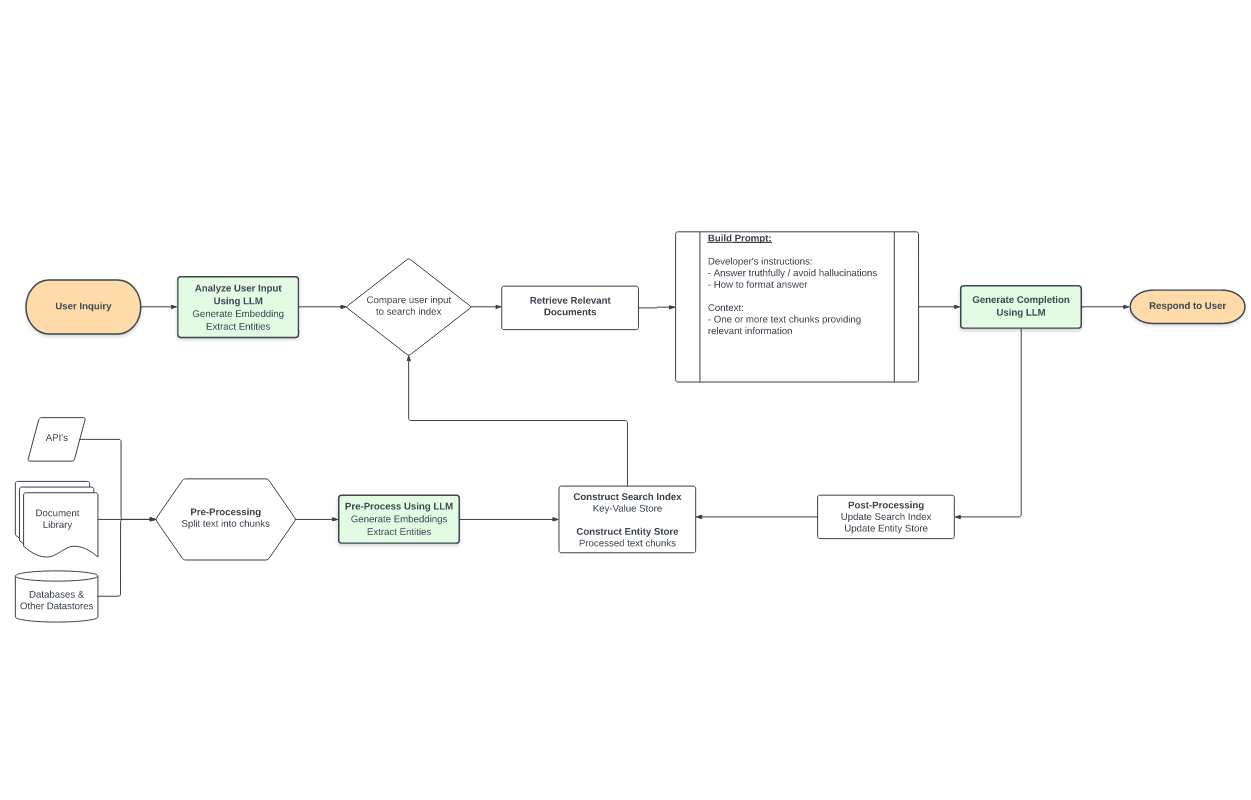
显然,这里的检索不只是面对非结构化文本的检索,而是包括了历史对话记录,历史API结果,历史用户操作记录等等等等。目前在这方面,开源工具库Llama-Index算是走的比较前的探索者,但也远远未到解决问题的地步。下图是一个标准的LLM时代的信息检索标准解决方案(来自于https://mattboegner.com/knowledge-retrieval-architecture-for-llms/):
- 全方位升级的人与Agent协作关系。
-
Agent与大模型的不同在于,大模型永远都只能被动的根据输入的prompt进行推理输出,而Agent是创造了整个思维运作体系。我们完全可以将Agent比作具备专业知识的特定职业专家,他的服务一定不是单纯被动响应的,而是存在主动发起的过程。并且服务形态也不应该仅限于对话框中的任务对接与同步执行,应该有全生命周期的服务。
举1个例子来说,Agent首先可以和我们共同读一本书,一起理解书中的内容,就一些点进行讨论。同时你可以安排一些定期的提醒任务给Agent,让其通知自己需要归还书籍。并且Agent还会在用户离线的情况下,持续的做用户交代的比如小说撰写的任务。
-
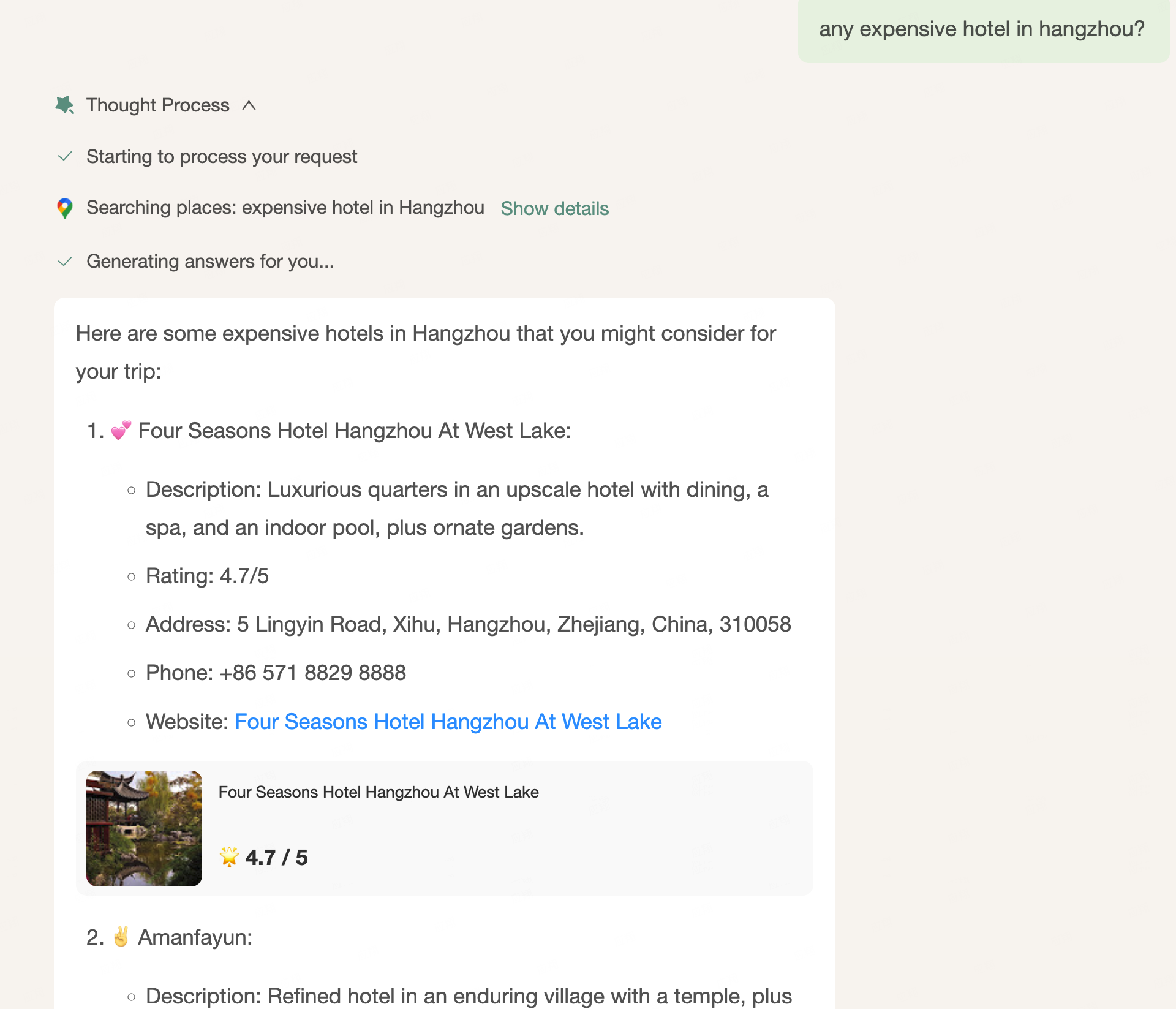
另外一个重要的点是,目前的软件的形态其实已经做了比较好的用户路径优化,在一定程度上交互的效率比自然语言要高,所以Agent与用户的交互界面应该是GUI-Mituring的,多模态的。这样也增强了信息传递的效率。下图来自 mindos.com
-
- 进化,学习能力
实际上,对于Agent来说,本身是需要不断进化,去更好的服务用户的。这里的进化包含了:自主学会新的Tool的使用(可以使用类似Voyager paper内提到的框架进行)也包含了对自己的一些内部运行prompt根据用户反馈进行修正(Auto Prompt Optimization)
另外一个方面,随着用户的使用,Agent不断沉淀对用户的认知,以用户的视角更好的去使用工具或者说是别的Agent,这也是适配于用户的进化。这里也包含了Agent应用持续的价值积累和壁垒构建。