Context is all you need
- 6 mins思考起源
在我看来,人类使用AI来提升生活质量、决策效率,对于AI有3个要求,intelligence, context, cost.
现在来看不管是gpt4o还是sonnet(甚至都不用O1和Opus),在面向大多数领域时,智力已经足够了,并且带有推理能力的通用大模型还将一直把智力发展下去。
cost作为另外一个比较重的制约因素,目前由通用大模型公司(OpenAI, DeepSeek)、云厂商、以及诸如together.ai这类的公司在完成。
然而AI在普通用户这个人群中,普及率还是比较低,还有一个重点问题,对于绝大部分用户问问题并交代背景不是一个很容易完成的事情,或者说“成本”太高。
这个问题用简单的短语描述,就是context 同步问题。
我们团队现在意图定义和解决的,就是这个问题。 我们选择的做法是,做一个Lifelong Personal Model的系统。
Context
什么是Context? 我把他定义为下面的三种:
- Inner Context: 人自己的思考,自己的认知,当时的情绪(由经历和记忆塑造)
- Intermediate Context: 人自己的记录(经历和记忆本身)
- Outer Context: 外部知识库,互联网信息(可以是未曾经历的,但是可以使用的,未来在团队协作中,也会存在另外一种Outer Context,协作context)
Google & Perplexity: 解决Outer Context问题。而RAG是解决Context的一种技术方案。 以前是用户自己解决其他部分Context的问题,现在由我们来解决。
以终为始
- 假设1:未来会有一个(或全球范围内不超过5个)通用的大模型服务商,提供像诸如天网一样的中心化的,智力密集的大模型服务。
- 假设2:人类的经历信息,会像物联网一样能上传到一个去中心化的存储(如果人权能保证,那么这是一个隐私保护的必然结果)。而人类的思想,火花,也会被诸如像neural link这样的技术所捕捉,采集。但一样,他会存储到一个去中心化的存储上。
可能存在的约束:
- 端侧模型的智能力,在有限的时间内不会无限成长。或者说云上通用大模型的智能力永远超过端侧的模型。
- 如果所有的交互都会被信息化,那么用户大部分数据需要在本地存储,以保障个人隐私。
基于此,我们可以定义下面的未来结构:
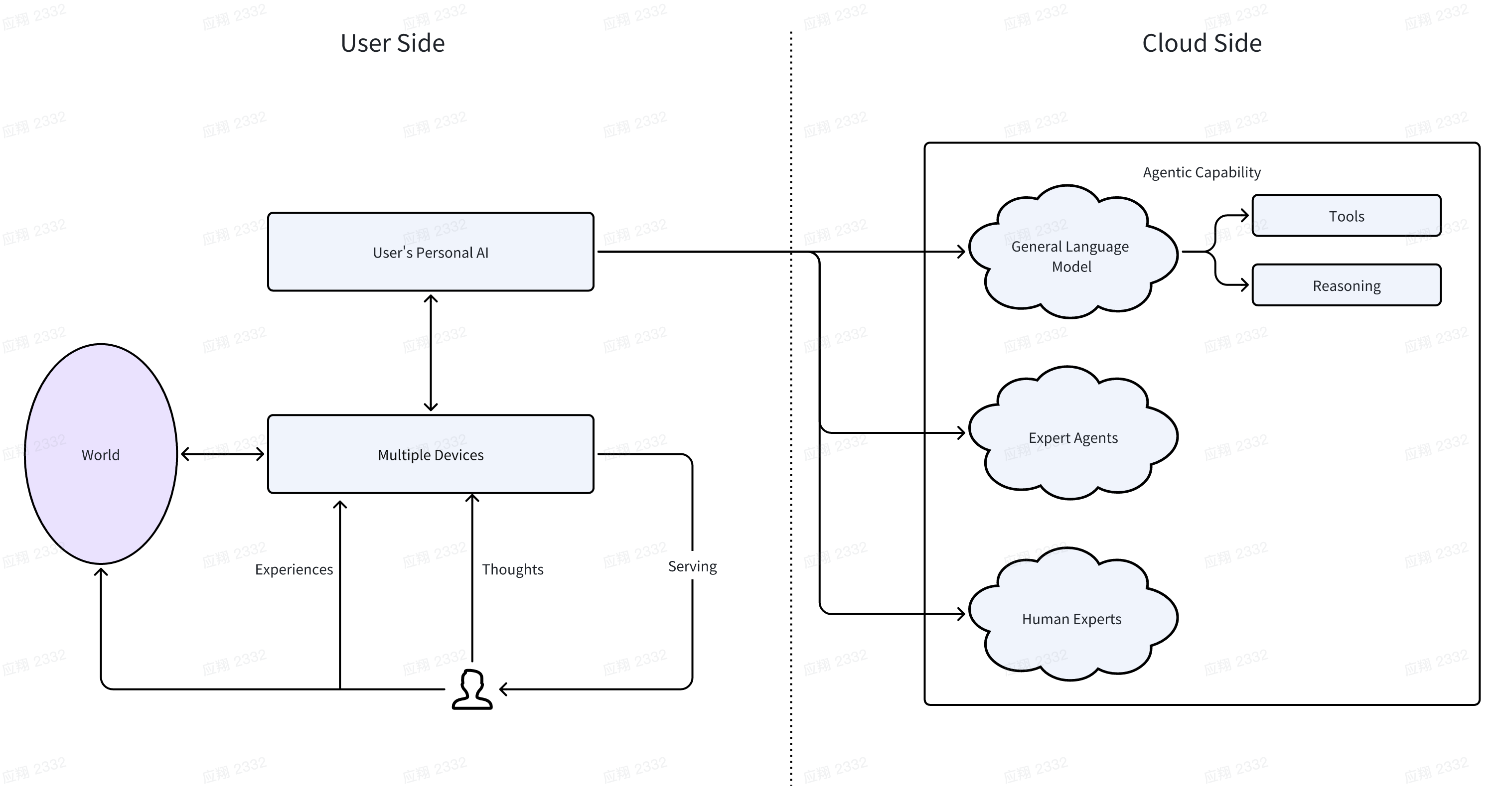
在这个图里,重点关系是这样定义的:
-
用户所需的服务由各类端侧设备提供,在提供服务的同时采集相关的信息。以目前的视角来看,设备包含手机、类似眼镜的设备、人形机器人、脑机接口。
-
端侧设备的服务由Personal AI来作为封装,整合进行提供。同时Personal AI需要端侧设备采集的数据来进行训练。以真正站在用户视角来提供context,解决问题。
-
当需要解决复杂场景问题的时候,用户的Personal AI会在保障隐私的情况下,和云上的通用大模型进行协作。此时主要的职责是判断以及提供更多符合用户的Context。
落地
材料
未来端侧设备的当前模拟:Me.bot,这个产品可以帮助用户进行日常想法和经历的多模态记录,并且能够支持用户沉浸式的基于记录与AI进行交互。 超强的通用大模型:gpt4o和Sonnet 3.5 User’s Personal AI: 我们的Lifelong Personal Model
目标需求
那么基于终局和现状,Lifelong Personal Model作为personal context的提供者,需要确定以下的学习目标:
- 提供个性化的交流体验
- 情感类情绪类交互
- 深度思考,知识类交互
- 提供纷繁信息世界的信息筛选及合成能力
- 每天有哪些信息是用户“需要”的
- LPM应该以怎么样的表达方式给到用户
- Agent Level的问题(简单不恰当例子:帮我去找一些最新的适合我阅读的arxiv paper)
- 调用工具或者通用大模型解决用户的实际问题。
能力明确
基于这些任务,我们的Lifelong Personal Model需要具备的能力是:
-
基于对用户的了解,真正站在用户视角(这一点的理解很关键,什么是真正站在用户视角,实际上这个时候就是用户的老妈,是用户的管家阿福)的基础问答。 也就是结合召回的信息,进一步补全更多的信息(召回必然有遗漏,但这个补全过程可能是模型内部隐式的),并做出基本的信息处理。
-
针对信息来源的进行信息的筛选。这可以帮助用户连接各类线上的APP。 需要模型的能力是一种基于用户长期需求 + 用户即时需求 + 偏好的通用信息筛选排序能力。
-
最有意思的,与通用大模型交互(专家)时,作为用户的管家(代表),站在用户的需求,立场的角度,给出判断,并提供更多的context。 需要模型的能力是基于当前需求,外部执行结果,用户自身偏好的reward 能力及context 补全能力。
技术实现
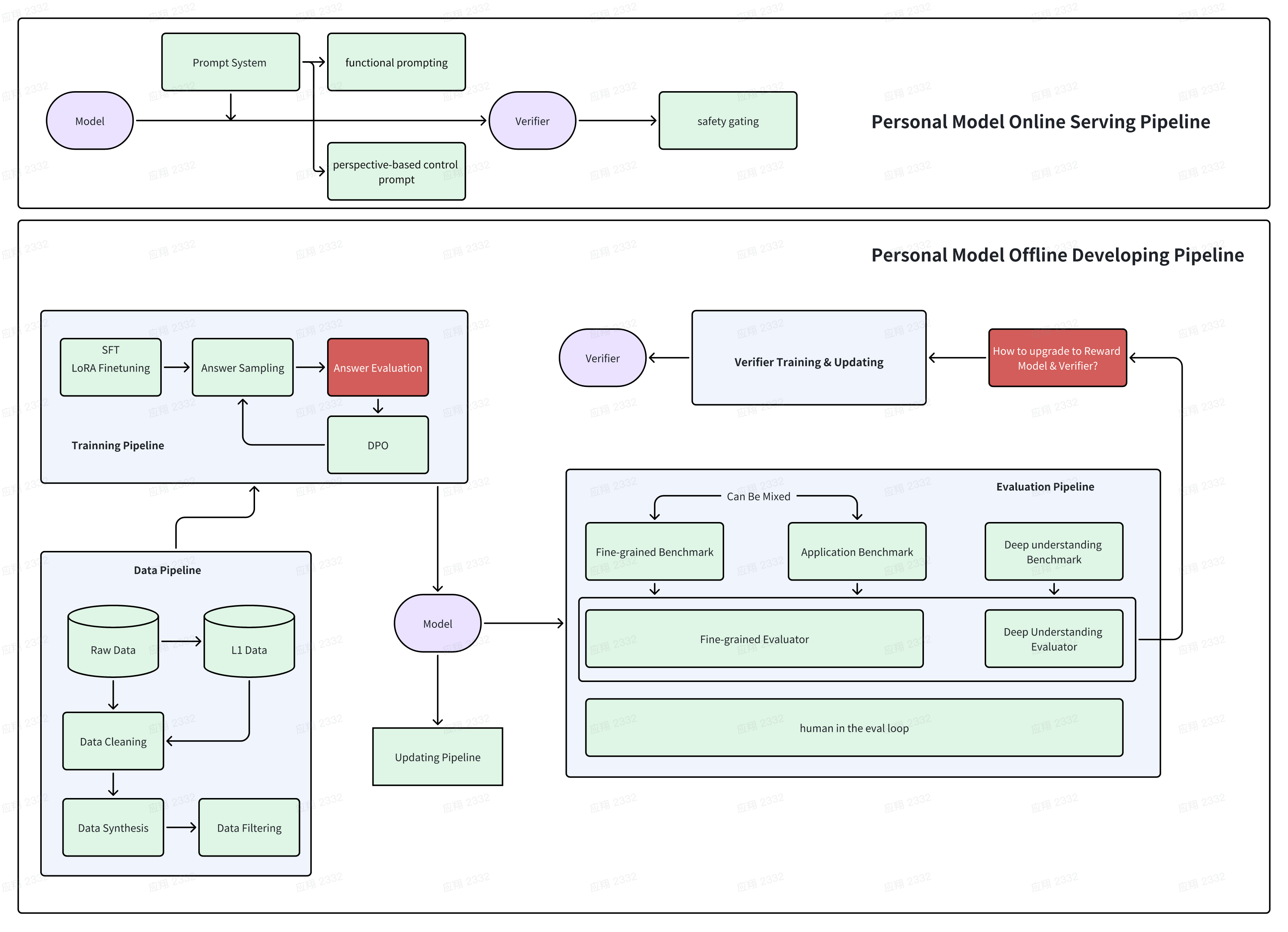
在定义完任务和模型能力的需求之后,任务变得清晰起来,虽然内里还有很多实质性的挑战,但技术实现也随之变得清晰起来。 首先Lifelong Personal Model应该是一个系统。由L0, L1, L2三层结构组成。
L0: 这是用户的碎片化信息层,记录了用户的多模态体验的原始数据。它专注于用户的个体事件,捕捉具体的事实和遭遇。
L1: 这是一个半结构化、个性化的信息层,基于心理学原理构建。它结合了多维度的用户特征,依托相关理论,同时包含表示用户与人、事件和事物之间关联的构念。这一层形成了一个压缩的、以用户为中心的主观信息网络,用于影响个性化体验。
L2: 为每位用户训练了一个拥有数十亿参数的大型语言模型,通过学习用户的经历,深入了解用户的偏好,并与用户的认知和倾向深度对齐。这一层支持对用户体验和思想的细致理解,提供灵活且高度个性化的使用支持。
我们将本文的重点放在L2,下图是我们的具体实现链路,具体的特殊点还是在数据的处理部分,我们之后细节聊,在投的Paper也即将更新。
反思对比
To be continued…