如何降低llm-based应用的模型调用成本
- 7 mins作为基于大模型的底层通用平台,和其他的llm-based应用一样,在基本功能已经稳定,第一阶段探索期过了之后,都需要考虑运行时的大模型调用成本问题,以达到既能满足用户,又使得成本足够低的目标。不过目前个人在这块的经验也还比较有限,下面的内容仅供参考。
两个误区
- gpt3.5的价格已经足够便宜了,做这些事的roi不高。
- 用户可以用自己的大模型key,我们的产品通过中间价值收大模型之外的钱。
这两个误区有一定道理,但从实际出发还是会对最终产品的体验造成影响。
针对第一点,在高要求的产品能力情况下,gpt4往往超过3.5太多,所以不得不使用4,价格就上去了。
针对第二点,不管是c端产品还是b端产品,如果真的想要覆盖更多的用户,真的想做ai平权,那你的大部分目标用户一定没有自己的key,更何况key的实际消耗要远远高于chatgpt plus,不考虑用户的开销也不是长久之计。
降成本设计
对于大模型调用开销来说,有几个要素,即模型种类,模型调用次数,调用模型的平均prompt长度,这些要素相乘即基本是最终开销:
\[cost = \sum_{i=1}^{n} (M_i \times C_i \times P_i)\]其中:
- n 表示模型的种类数目
- M_i 表示第 i 种模型的调用次数
- C_i 表示第 i 种模型每次调用的平均prompt长度
- P_i 表示第 i 种模型的单价
再换另外一个使用侧的时间线的视角,大模型使用的生命周期有三个节点:
- 是否调用大模型
- 调用哪个模型
- 用什么prompt调用
那这三个节点分别可以做些什么具体工作来降低成本呢?先简单看下图:
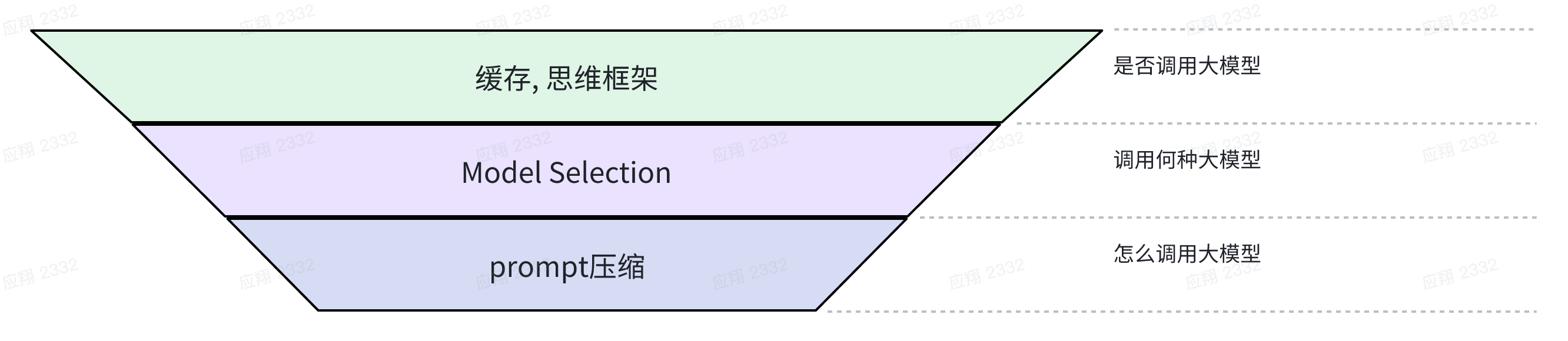
这三个节点是后序节点依赖前序节点,控制的力度是从粗到细的。
第一个生命周期:是否调用大模型
1. 缓存(Cache)
大原理和常规请求缓存一致。区别在于对命中缓存的设计。这里采用的是文本相似度的衡量方法。最常见的两种是:基于编辑距离(Edit Distance)和基于语义相似度(Semantic Similarity)。
因为在绝大多数情况下,上下文是千变万化的,为了保障用户的体验,这种非精确也难以精确的方法一般采取宁可错过,不可杀错的原则。(可以不命中缓存,命中缓存的说明在和缓存中的内容十分十分相近的)所以Edit Distance的阈值会设置的比较小,而语义相似度的阈值会设置的相当高。
一般来说,缓存的方案在对话流中对成本的节约十分有限,更多的是最开始开场的几句话或者说将大模型作为无状态的问题解决器时起到作用。
具体的缓存机制不在这篇文章进行讨论,而且有更多的人比我更清楚。
2. 认知推理框架
类似于autogpt这种agent框架,或者babyagi,更多的是理念型的传达而不过度考虑成本。所以每次可能需要决策的地方都会选择去决策,每次决策也基本倾向于使用最好的模型。
再到更细致具体的xxx of thought类的学术工作,除了朴素的chain of thought和一切奇技淫巧(比如一些对比thought啥的),很多如tree of thouht,graph of thought,都会存在多次调用。
那么解决办法当然是更加合理的利用”脑力”资源——设计一套认知框架,让单位llm价格完成的任务尽可能达到上界。用人话来说即对于每次llm的调用,任务都可以复杂到大模型能单次就能解决的上限,以此来提高大模型的推理算力(其实也是价格)的利用率。
具体的执行在这个环节里我们是这么做的:先参考认知科学的system 1和system 2思考设计宏观的认知框架,然后根据实际的线上调用情况,推得不同环节任务的难度,以及找出可以妥协的环节,进行经验主义的抠细节,积小胜为大胜。
第二个生命周期:调用何种大模型
在决定的调用大模型之后,我们可以进行下一个选择——调用哪个大模型。单看openai的模型,最简单的也有gpt3.5和gpt4,更不用说还有google的gemini,开源的llama,或者国内其他的大模型。
我们的指导思想还是上面的理论,我们应该让单位llm价格完成的任务尽可能达到上届。
所以当实在无法找到10倍难度任务的时候,我们应该积极的选择gpt3.5。在这样的情况下,我们的成本可以这样表示:
\[B_{total} = B_{GPT4} \times N_1 + B_{GPT3.5} \times N_2 + N_{total} \times B_{small}\]其中:
- B_total 表示总成本
- B_GPT4 表示GPT-4的单次调用成本
- N_1 表示GPT-4的调用次数
- B_GPT3.5 表示GPT-3.5的单次调用成本,基本可以是1/10的B_GPT4
- N_2 表示GPT-3.5的调用次数
- N_total 表示总的调用次数,是N_1和N_2之和
- B_small 表示小模型的单次调用成本
在这里我们可以采取supervised learning的方案。针对成本占比最高,最核心的环节(优化这个模块的roi是最高的),结合上下文进行人工+AI的协作打标,打标的标签为二分类标签(必须使用gpt4,非必须使用gpt4)。打标对象是从真实线上记录采样得到的样本和这些样本再次调用gpt3.5得到的结果。打标方案是让gpt4在不知道两个结果的模型来源时,来判断是否有明显的差异。然后人工进行审核。
有了数据之后我们就可以使用seq2seq的model,来进行模型的training。
进一步的,我们可以设计更好的模型pipeline(如怎么样更好的让用户帮助我们标注数据,是否用更好的foundation model,是否用类似于dpo的方法来进行更好的训练,如何进行线上模型的替换)来进行优化。
额外提一嘴,zoom的黄学东老师提出的Federated AI应该也是采用了类似的方案,当然肯定进行了更多zoom化的适配以及更深的打磨。(https://www.zoom.com/en/blog/zoom-federated-ai-maximizes-performance-quality-affordability/)
第三个生命周期:怎么调用大模型(prompt)
这部分的工作在这里我最喜欢的工作是llmlingua系列(目前看到的有llmlingua和longllmlingua),从标题中透出的思想很美(llm有自己的语言体系,说很多废话是为了迎合人类,注意后半句是我自己加的)
总体的做法就是:通过一个微微对齐的小模型得到的ppl,和一个预先设定的压缩比,进行多尺度的prompt token裁剪。大的逻辑是ppl小的无需保留,因为可以大模型自己推理得到,更多保留困惑度高的内容。如果我没记错的话,很多任务可以变成1/4甚至更低的prompt token长度,同时效果基本打平。
具体的方法请各位自行去阅读论文,或者部分已经由作者集成到了llama index的开源项目中。我们团队也根据论文指导进行了实现,发现在我们的任务中,也能起到不错的效果。
后话
最终,流量上来了之后,如果真的觉得roi够高,可以考虑self hosted。那就又是另一个长篇故事了…组batch,剪枝,蒸馏,更好的底层推理框架,balabala…
再从更长期的来看,最好的模型的推理成本总会降低,这样说充分使用模型的决策的框架也没有错。所以对于成本来说,最终一定是短期超额投入以保障短期获益的一种局部优化行为。